
Une des questions qui revient presque systématiquement lorsque je présente Miralia, c’est :
« Quelle est la différence entre votre IA et ChatGPT (ou les autres LLM) ? »
La réponse courte tient généralement en quelques mots.
Les LLM sont remarquables pour générer du texte : ils produisent des réponses fluides, cohérentes, parfois impressionnantes. Leur fonctionnement repose toutefois sur des mécanismes probabilistes : ils estiment, à partir d’un contexte donné, quelle est la suite la plus vraisemblable d’un point de vue statistique.
Chez Miralia, l’approche est différente. Notre IA est construite sur des mécanismes de NLU : elle est conçue non pas pour produire du texte, mais pour comprendre des messages, qualifier des situations et prendre des décisions de manière structurée. Et surtout, cette compréhension est explicable.
À ce stade, la question suivante arrive presque toujours :
« Mais ChatGPT peut aussi expliquer ce qu’il fait, non ? Il suffit de lui demander pourquoi. »
La réponse est : oui… mais non.
Et c’est précisément cette nuance, souvent mal comprise (y compris par des profils techniques), qui m’a donné envie d’écrire cet article. Car derrière cette apparente similitude se cachent en réalité deux types de systèmes fondamentalement différents, avec des implications majeures dès lors que l’IA sort du simple assistant conversationnel pour entrer dans des contextes métiers, opérationnels et réglementés. Avant d’entrer dans des cas concrets, faisons un détour par la théorie.
Pour comprendre pourquoi la question de l’explicabilité est souvent mal posée lorsqu’on parle de LLM, il faut d’abord comprendre ce qu’est réellement un LLM, et surtout ce qu’il optimise.
Qu’est-ce qu’un LLM, concrètement ?
Un Large Language Model est un modèle statistique entraîné sur de très grands volumes de texte, dont l’objectif fondamental est simple :
prédire la suite la plus probable d’une séquence de symboles, étant donné un contexte.
Ce point est essentiel, un LLM n’est pas conçu pour comprendre, raisonner ou décider, il est conçu pour estimer une probabilité.
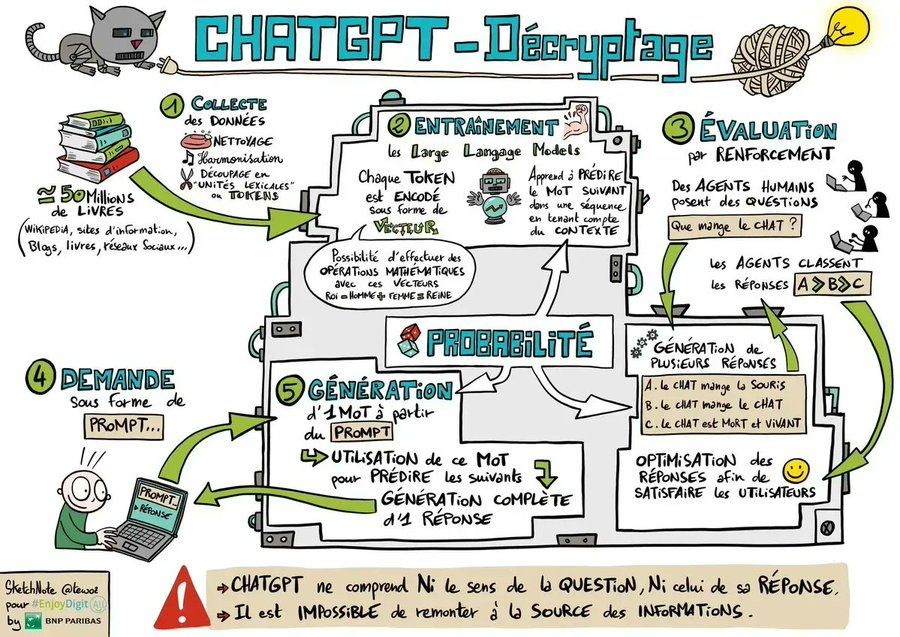
Du texte aux tokens
La première étape du traitement consiste à transformer le texte brut en tokens. Ces tokens ne correspondent pas nécessairement à des mots. Il s’agit le plus souvent de fragments de mots (subwords), définis par un tokenizer afin de couvrir efficacement un vocabulaire très large.
À ce stade :
- le modèle ne manipule pas de phrases,
- pas de concepts,
- pas d’intentions,
- pas de règles.
Il manipule une suite discrète de symboles, sans signification intrinsèque.
Tokens et absence de sémantique explicite
Il est important de souligner que la tokenisation ne porte aucune sémantique métier ou conceptuelle. Un token n’est ni un mot, ni une idée, ni une intention. C’est une unité de calcul.
La sémantique n’est pas encodée explicitement dans les tokens, mais émerge indirectement de leur usage statistique dans les données d’entraînement.
Tokens → embeddings → espace latent
Chaque token est ensuite projeté dans un vecteur numérique appelé embedding. Ces embeddings vivent dans un espace latent de grande dimension, construit pendant l’entraînement du modèle. Dans cet espace :
- des contextes statistiquement proches sont représentés par des vecteurs proches,
- des contextes éloignés par des vecteurs éloignés.
La “compréhension” d’un LLM repose donc entièrement sur :
- des relations de proximité mathématique,
- pas sur des catégories explicites,
- ni sur des règles formalisées.
Le cœur du modèle : la prédiction
Une fois les embeddings calculés et agrégés, le modèle produit une seule chose, une distribution de probabilité sur le prochain token. À chaque étape, le LLM répond à la question :
“Sachant le contexte précédent, quel token est le plus probable ensuite ?”
Même lorsqu’on lui demande :
- de produire un résumé,
- de répondre à une question,
- de renvoyer une structure JSON,
- de “classer” ou “évaluer” un texte,
le mécanisme sous-jacent reste strictement le même : la génération probabiliste de symboles.

Pourquoi cela n’est pas une décision
Dans un LLM, il n’existe pas de notion explicite de :
- critère,
- seuil,
- règle,
- chemin de décision.
La sortie produite peut ressembler à une décision, mais elle n’est que le résultat d’un calcul probabiliste continu. Il n’y a pas de point précis dans le calcul où l’on pourrait dire :
“Cette condition a été déclenchée.”
Conséquence directe sur l’explicabilité
Puisqu’un LLM ne produit pas de décision formelle, il ne peut pas fournir d’explication formelle. Lorsqu’on lui demande :
“Pourquoi as-tu répondu cela ?”
il ne fait qu’appliquer exactement le même mécanisme :
- transformer la question en tokens,
- prédire une suite de tokens plausible,
- produire un discours explicatif cohérent.
Cette explication est linguistiquement convaincante mais décorrélée du chemin de calcul réel.
Elle ne constitue pas une justification causale, mais une reconstruction a posteriori. Ce point est central pour la suite. Cette propriété n’est ni un défaut, ni une faiblesse accidentelle, c’est la manière dont est conçu le LLM.
Pour comprendre pourquoi une approche fondée sur le NLU permet l’explicabilité, il faut changer de cadre mental. On ne parle plus de génération probabiliste, mais de représentation explicite du sens et de raisonnement structuré.
Qu’est-ce qu’un système NLU, concrètement ?
Un système de Natural Language Understanding n’a pas pour objectif de produire du texte, son objectif est de transformer un message en une représentation structurée, interprétable et exploitable par un système.
Autrement dit, un NLU ne cherche pas à prédire une suite de symboles, il cherche à qualifier une situation. Cette différence d’objectif entraîne une différence radicale d’architecture.
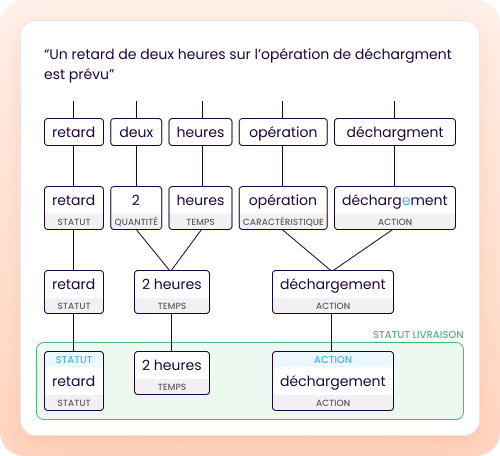
Du texte à une représentation linguistique explicite
La première étape d’un système NLU consiste à analyser le texte pour en extraire des unités linguistiques interprétables. Contrairement à la tokenisation subword des LLM, ces unités ont une signification fonctionnelle :
- segments,
- expressions,
- patterns,
- structures syntaxiques ou sémantiques.
L’objectif n’est pas de couvrir un vocabulaire arbitrairement large, mais de repérer des éléments porteurs de sens.
Intention, entités, signaux : des objets nommés
Un système NLU repose sur des concepts explicites, généralement de trois types :
- Intentions : ce que le message cherche à faire
- Entités : des éléments identifiables et typés
- Signaux : des indices linguistiques ou sémantiques pertinents
Ces objets ont plusieurs propriétés clés :
- ils sont nommés,
- ils sont documentés,
- ils sont observables dans le pipeline de traitement.
Ils constituent une représentation intermédiaire stable, ce qui est précisément ce qui manque dans un LLM.
Une représentation structurée, pas un espace latent
Là où un LLM projette le texte dans un espace latent non interprétable, un NLU construit une représentation symbolique ou semi-symbolique. Cette représentation peut prendre la forme de :
- variables booléennes,
- catégories,
- scores explicites,
- listes d’éléments détectés.
Point essentiel, chaque élément de cette représentation a un rôle fonctionnel clair. Il ne s’agit pas de proximité statistique, mais de qualification explicite.
Du sens à la décision : règles, logique, déterminisme
Une fois la représentation linguistique construite, le NLU passe à une seconde phase, distincte : l’application d’une logique de décision explicite.
Cette logique peut reposer sur :
- des règles,
- des priorités,
- des pondérations,
- des seuils,
- des combinaisons conditionnelles.
Le point clé est que cette logique est :
- séparée de l’analyse linguistique,
- lisible,
- modifiable,
- versionnable.
Le système ne “devine” pas une sortie. Il applique une logique définie à une représentation explicite.
Le cœur du NLU : un chemin de calcul observable
Dans un NLU, il existe un chemin de calcul clair :
- le texte est analysé,
- des éléments sont identifiés,
- des règles sont évaluées,
- une décision est produite.
Chaque étape est identifiable, observable et rejouable.
On peut répondre précisément à la question : “Qu’est-ce qui a conduit à cette décision ?”
Pourquoi cela rend l’explicabilité possible
L’explicabilité n’est pas ajoutée après coup. Elle est une propriété émergente du système.
Puisque :
- les éléments pris en compte sont nommés,
- les règles appliquées sont connues,
- les seuils sont explicites,
l’explication consiste simplement à décrire ce qui s’est réellement passé, il n’y a pas de reconstruction narrative, il n’y a pas de génération d’un discours explicatif indépendant.
Différence fondamentale entre LLM et NLU
| Dimension | LLM (Large Language Model) | NLU (Natural Language Understanding) |
| Représentation intermédiaire | Diffuse, dans un espace latent | Structurée, composée d’objets explicites |
| Nature du raisonnement | Distribué sur des millions de paramètres | Explicite, fondé sur des règles et des signaux identifiables |
| Chemin de calcul | Non localisable pour un cas individuel | Observable et traçable étape par étape |
| Prise de décision | Implicite, issue d’une génération probabiliste | Formelle, issue d’une logique déterministe |
| Explicabilité | Reconstruction a posteriori | Native, intégrée au raisonnement |
| Reproductibilité | Non garantie à l’identique | Garantie à entrée identique |
| Auditabilité | Très limitée | Nativement possible |
Une conséquence directe sur l’explication
Lorsqu’un système NLU explique une décision, il ne “parle pas de lui-même”, il expose son raisonnement réel. C’est ce qui rend possible :
- l’audit,
- la contestation,
- la reproductibilité,
- la conformité réglementaire.
Et c’est précisément ce point qui rend la comparaison directe entre NLU et LLM si trompeuse.
Comparaison sur un cas simple : une phrase de déclaration de sinistre
Maintenant que les bases théoriques sont posées, il est temps de quitter le terrain des concepts pour regarder ce que cela implique concrètement. Car ces différences de représentation et de calcul ne sont pas abstraites : elles produisent des effets très réels dès que l’IA est confrontée à une situation opérationnelle. Voyons donc, sur un cas concret, ce que ces deux approches impliquent réellement lorsqu’il s’agit de comprendre, décider… et expliquer. Prenons une phrase volontairement simple, telle qu’on peut en trouver dans un email :
« J’ai eu un dégât des eaux hier soir, l’eau venait de l’appartement du dessus et a abîmé mon plafond. »
L’objectif du système n’est pas de répondre avec du texte, mais de comprendre la situation afin de déclencher le bon traitement :
- qualifier le type de sinistre,
- identifier des éléments importants,
- décider de la suite du processus.
Voyons maintenant comment cette phrase est traitée selon l’architecture utilisée.
Comment cette phrase est traitée par un LLM
1. Entrée et transformation interne
La phrase est d’abord transformée en tokens, puis projetée dans un espace latent via des embeddings. À ce stade, le système ne manipule ni “sinistre”, ni “dégât des eaux”, ni “responsabilité d’un tiers” comme concepts explicites. Il manipule une représentation vectorielle globale du texte.
2. Génération d’une sortie
Si on demande au LLM de qualifier la situation, il peut produire une sortie structurée, par exemple :

Cette sortie est plausible, souvent correcte, et peut même être très fiable en pratique.
3. Où se situe la décision ?
La “décision” ici n’est pas le résultat d’un raisonnement formel. Elle est le résultat d’une génération probabiliste contrainte : parmi toutes les sorties possibles, celle-ci est statistiquement la plus cohérente avec le contexte.
4. Et l’explication ?
Si l’on demande ensuite :
« Pourquoi as-tu identifié un dégât des eaux provenant d’un tiers ? »
Le LLM peut répondre :
« Parce que le message mentionne un dégât des eaux et précise que l’eau provenait de l’appartement du dessus, ce qui indique une origine externe. »
Cette explication est compréhensible, convaincante et, il est vrai, bien formulée. Mais elle est générée après coup, sans lien formel avec le chemin de calcul réel. Elle ne permet pas de dire quels éléments précis ont été déterminants, ni comment ils ont été pondérés.
Comment cette phrase est traitée par un NLU
1. Analyse et extraction explicite
Le système NLU commence par transformer la phrase en une représentation structurée.
Il identifie explicitement des éléments comme :

Ces éléments ne sont pas implicites, ils sont nommés, traçables et observables dans le pipeline.
2. Qualification de la situation
À partir de cette représentation, le NLU applique une logique explicite :
- Si
water_damage = true→ catégorie “Dégât des eaux” - Si
third_party_origin = true→ origine externe - Si
material_damage = true→ ouverture de dossier possible
3. Décision formelle
La décision finale peut alors être exprimée ainsi :

4. Où se situe l’explication ?
Ici, l’explication n’est pas produite après la décision. Elle est la décision. On peut dire précisément :
- quels signaux ont été détectés,
- quelles règles ont été activées,
- pourquoi cette action a été déclenchée.
Et surtout, cette explication est stable dans le temps, rejouable et indépendante de la manière dont on la formule.
Ce que cette comparaison met en évidence
Sur une phrase simple, les deux approches peuvent produire un résultat similaire, la différence n’est donc pas immédiatement visible dans la sortie, elle est visible dans ce qu’il est possible de démontrer ensuite.
- Le LLM fournit une interprétation plausible.
- Le NLU fournit une qualification formelle.
Cette distinction devient décisive dès que :
- la décision a un impact réel,
- elle doit être expliquée,
- elle peut être contestée,
- elle doit être auditée.
C’est précisément là que la question de l’explicabilité cesse d’être théorique.
Conclusion – une différence subtile, aux conséquences majeures
Sur des exemples simples, la différence entre un LLM et un NLU peut sembler subtile. Les deux approches peuvent produire des résultats similaires, parfois même indiscernables à première vue, mais cette proximité est trompeuse.
Dès que l’on passe à des cas plus complexes, des situations ambigües, des parcours non linéaires, des décisions qui déclenchent des actions concrètes, la différence devient majeure.
Lorsqu’une IA :
- retarde une indemnisation,
- déclenche un contrôle,
- refuse un dossier,
- priorise une demande plutôt qu’une autre,
elle ne produit plus simplement une réponse, elle agit.
Dans ces contextes, la capacité à expliquer une décision n’est pas un confort, c’est une exigence fondamentale. S’appuyer sur des décisions issues de mécanismes purement probabilistes, sans chemin de raisonnement formel, revient à accepter une part d’arbitraire, une opacité structurelle, une responsabilité diluée.
Or, lorsqu’il y a un impact humain, financier ou juridique, ce choix n’est pas neutre, c’est précisément pour cette raison que le cadre réglementaire évolue. Avec l’AI Act, l’Europe affirme un principe clair :
Les systèmes d’IA qui influencent des décisions sensibles doivent être compréhensibles, traçables et justifiables.
Autrement dit, ne pas laisser des décisions critiques reposer uniquement sur des probabilités n’est plus seulement une bonne pratique, c’est un devoir et de plus en plus, une obligation.
C’est à l’aune de cette responsabilité, technique, éthique et réglementaire, que les choix d’architecture prennent tout leur sens.
Et les SLM, alors ?

À ce stade, une autre objection apparaît souvent, surtout chez des interlocuteurs plus techniques :
« D’accord pour les LLM. Mais qu’en est-il des SLM ? Ils sont plus petits, plus spécialisés, plus frugaux. Est-ce que cela ne les rend pas, de facto, plus explicables ? »
La question est légitime. Et la réponse mérite la même précision que précédemment : oui… mais non.
Pour comprendre pourquoi, il faut repartir exactement du même point que pour les LLM : non pas la taille du modèle, mais ce qu’il optimise réellement.
Un SLM optimise la même chose qu’un LLM
Un Small Language Model n’est pas une autre catégorie de système. C’est une réduction d’échelle, pas un changement de nature. Comme un LLM, un SLM est entraîné pour : prédire la suite la plus probable d’une séquence de tokens, étant donné un contexte.
La chaîne interne reste strictement identique :
tokenisation → embeddings → projection dans un espace latent → génération probabiliste.
La seule différence porte sur, le nombre de paramètres, la taille du corpus, le coût et la latence d’inférence.
Mais le mécanisme fondamental ne change pas.
Un SLM :
- ne manipule pas davantage de concepts explicites,
- ne dispose pas de règles internes identifiables,
- ne produit pas de chemin de décision formel.
Il calcule, comme un LLM, une distribution de probabilité.
Ce que la réduction de taille change… et ce qu’elle ne change pas
La réduction de taille a des effets réels :
- des comportements souvent plus stables,
- une surface d’erreur plus limitée,
- une meilleure maîtrise opérationnelle,
- une frugalité accrue en ressources.
Cette stabilité améliore la prédictibilité globale du système, mais elle ne crée aucun lien explicite entre une entrée donnée et la décision produite pour ce cas précis, elle ne crée aucune structure de raisonnement nouvelle.
Il n’apparaît toujours pas :
- de critères métier explicites,
- de seuils observables,
- de logique décisionnelle séparée,
- de représentation intermédiaire interprétable.
Autrement dit, le calcul est plus petit, mais il reste opaque du point de vue du raisonnement causal et décisionnel.
L’illusion d’explicabilité renforcée
C’est ici que la confusion est la plus fréquente.
Parce qu’un SLM est plus prévisible, plus contraint, plus cohérent sur un périmètre donné, il donne parfois l’impression d’être plus explicable. Mais cette explicabilité est, là encore, linguistique, pas causale.
Lorsqu’on demande à un SLM :
« Pourquoi as-tu pris cette décision ? »
il applique exactement le même mécanisme que pour produire la décision elle-même :
- transformer la question en tokens,
- générer une réponse plausible,
- reconstruire un raisonnement a posteriori.
Cette réponse peut être pertinente, convaincante, alignée avec l’intuition humaine, mais elle reste décorrélée du calcul réel. La taille du modèle n’a rien changé à ce point fondamental.
SLM vs NLU : la même frontière qu’avec les LLM
On retrouve donc exactement la même ligne de fracture que précédemment.
Ce n’est pas LLM vs SLM
C’est :
- modèle génératif probabiliste vs système de compréhension et de décision explicite.
Tant qu’un système génère ses sorties par estimation statistique,
- sans objets métier nommés,
- sans règles formelles,
- sans chemin de calcul traçable,
il ne peut pas produire d’explication native, au sens audit, contestation, reproductibilité ou conformité réglementaire.
Rendre un modèle inspectable ou mesurable ne suffit pas à le rendre explicable. Visualiser des poids, des activations ou des scores d’importance globale ne permet pas de reconstruire un chemin de décision pour un cas individuel, ni d’identifier formellement les critères ayant conduit à l’action.
Pourquoi cela compte réellement
Dans des usages d’assistance, de suggestion ou de support, cette distinction peut sembler secondaire.
Mais dès que l’IA qualifie une situation métier, déclenche une action, influence un processus réel, la question n’est plus :
« Est-ce que le modèle est petit ? »
Mais :
« Peut-on démontrer ce qui a conduit à cette décision ? »
Et sur ce point précis, SLM et LLM sont dans le même camp. La taille du modèle change le coût. Elle ne change pas la nature de l’explication.
Du point de vue de la responsabilité juridique et réglementaire, un SLM reste dans la même situation qu’un LLM : il est impossible de démontrer formellement pourquoi une décision précise a été prise à un instant donné. Réduire un LLM en SLM ne transforme pas une IA générative en IA explicable : la frugalité change le coût, pas la responsabilité. Ce qui fait l’explicabilité, ce n’est pas la taille du modèle, mais l’existence d’un raisonnement explicite — et c’est précisément ce que permet le NLU.
